Keeping up with the latest on arXiv is hard ask, and requires somehow sifting through hundreds of papers every day. While I spent a long time relying on my network to surface important papers for my particular interests, this usually biases me towards a subset of authors or labs that are particularly adept at becoming popular on social media.
ArXiv-Sanity is a great solution to this problem, allowing you to find recommended papers based on TF-IDF vectors for papers. While it works well, I wanted to explore an approach based on some of my prior personalization work that uses a simpler “like” and “dislike” option to learn which papers are interesting or relevant for a user. The code is available publicly, and I created a fairly easy-to-adapt workflow to spin it up on your machine every day!
How it works
When you create an account, you are assigned a randomly-initialized a personal embedding. As you “like” or “dislike” papers, your embedding moves closer to papers you like and further from those you don’t. This means your paper recommendations become increasingly tailored to your interests over time (as long as you’re liking/disliking relevant papers).
The amount of movement is determined by a hyper-parameter that is set in the code, but theoretically you can either (1) change this yourself or (2) repeatedly “Like” or “Dislike” papers to move your embedding faster.
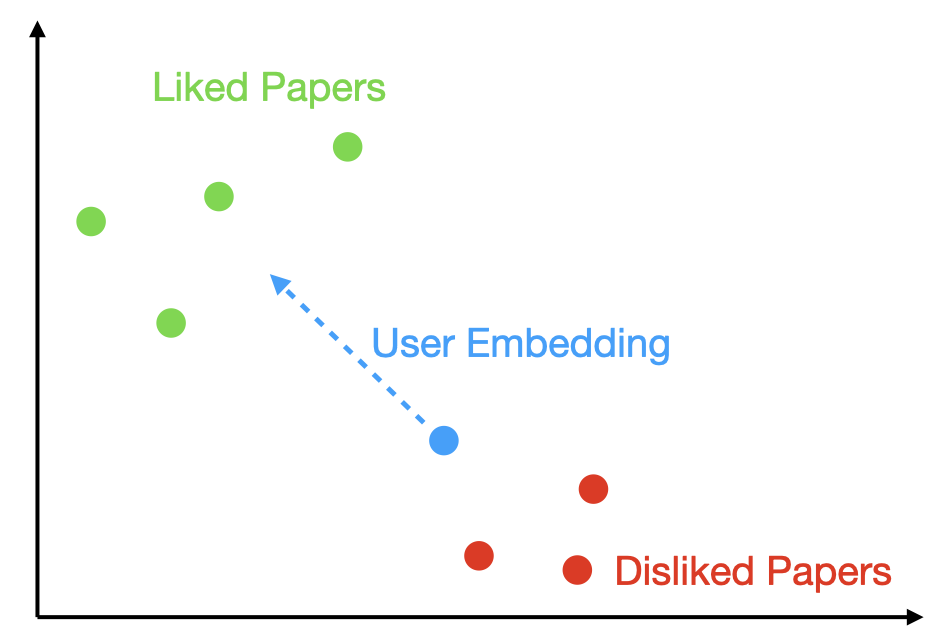
I’ve also built-in the ability to export or import personal embeddings, so you can borrow a warm-start from somebody with similar interests (or share your embedding with a friend). There is an example embedding included in the repo that serves as a warm-start for personalization/LLM research.
Finally, I’ve added a daily_process script that will automatically download papers, compute their embeddings, and spin up a local instance of the app for 3 hours.
I’ve configured this to run on my work computer everyday at 8:00AM, and it’s pretty handy for quickly skimming the day’s related works!
Implementation details
Under the hood, I’m using Hugging Face’s sentence-transformers to generate paper embeddings from abstracts. I’ve hard-coded the model to all-mpnet-base-v2, but of course this can be swapped out for whatever (just keep in mind, it will render your personal embedding useless, and you’ll need to update the hyperparameter for the user embedding dimensionality accordingly!).
Upon running Andrej’s script to download arXiv papers, we then embed all of the papers into 768-dimension vectors, and save them to a local database. When a user starts up the application, papers can be sorted by “recommended”, which ranks papers according to the user’s interests. The papers are embedded with a consistent string, which is computed as:
'Title: {title}. By: {author_list}. Abstract: {abstract}'
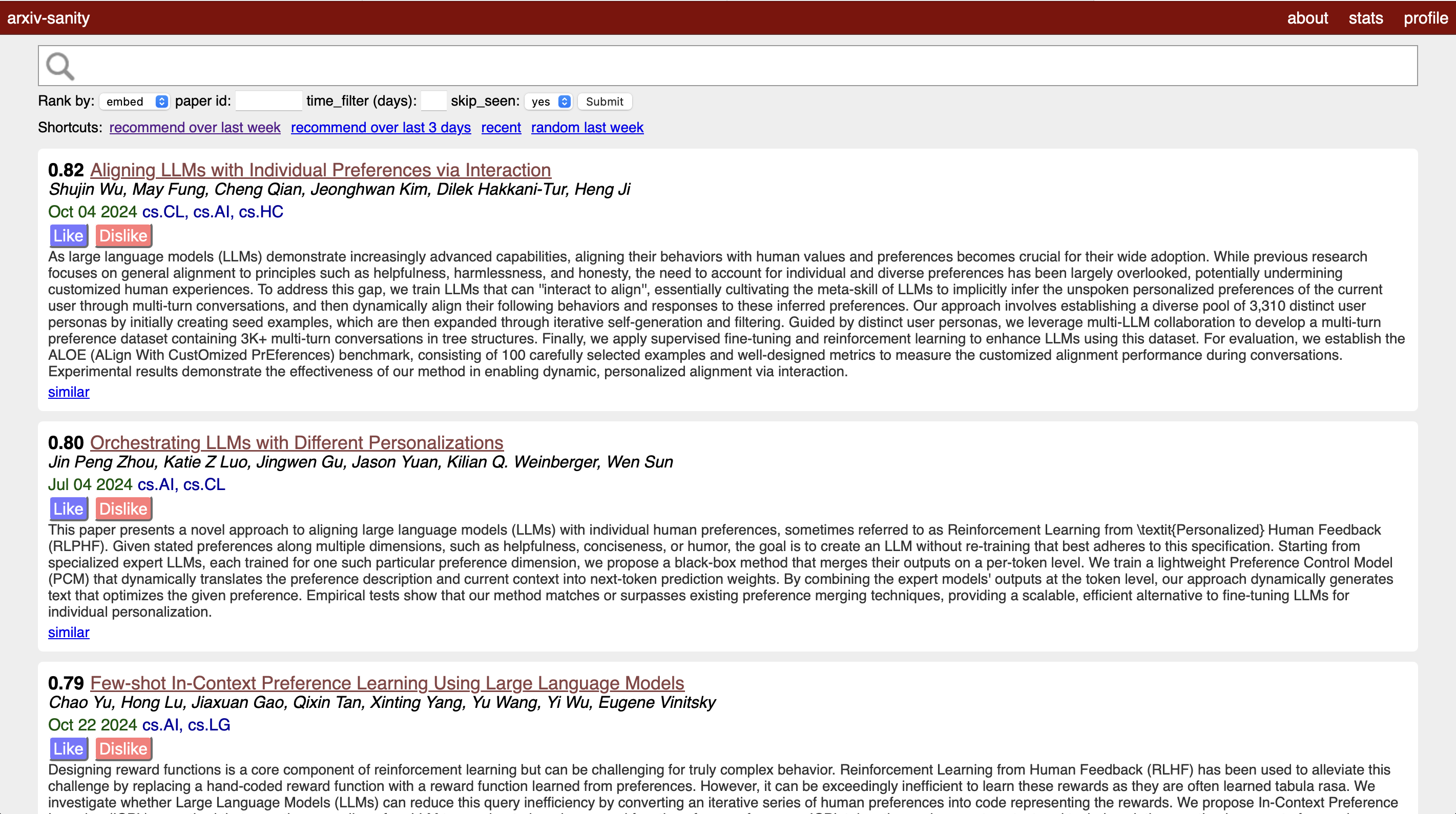
If you sort by recommended, all papers will be ranked based on their similarity to your personal embedding (ranked by cosine-similarity), so more similar papers are ranked higher.
The actual cosine similarity number is shown next to each paper on the site.
Note that the current implementation is personalizing by minimizing euclidean distance, but ranking by cosine similarity.
In practice, it seems to work well enough!
Try It Out
The project is open-source and available on GitHub. If you’re interested in running your own instance or contributing to the project, check out the repository. If you try it out, I’d love to hear your feedback!
Acknowledgments
This work builds upon Andrej Karpathy’s excellent arxiv-sanity-lite project and leverages Hugging Face’s powerful [sentence-transformers library]((https://sbert.net).