I recently read Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward and found it an interesting read, so I figured I’d write a quick summary and some thoughts on the work.
Motivation
We want to personalize LLMs in situ and without assuming access to labeled preference datasets for users. If we treat the user as a world that the LLM must explore, then a curiosity or intrinsic exploration reward should help us to discover the user’s innate preferences more quickly and effectively.
Method
In this work, the authors use an LLM as a synthetic human (the “Environment Model”, because the user is likened to the environment in conventional reinforcement learning). The core of the method then relies on 3 other LLMs. One converses with the “human” (this is the LLM we’re learning/updating, called the “Policy Model”). The next scores the finished conversation and generates the task reward (the “Reward Model”). And finally, one LLM (the “User Model”) predicts a dense, turn-based reward based on how well the conversation (between the Environment Model and Policy Model) enables the User Model to infer the synthetic user’s preferences. The Environment Model, Policy Model, and Reward Model are all Gemma 2B checkpoints, and the User Model is a Gemma 7B checkpoint.
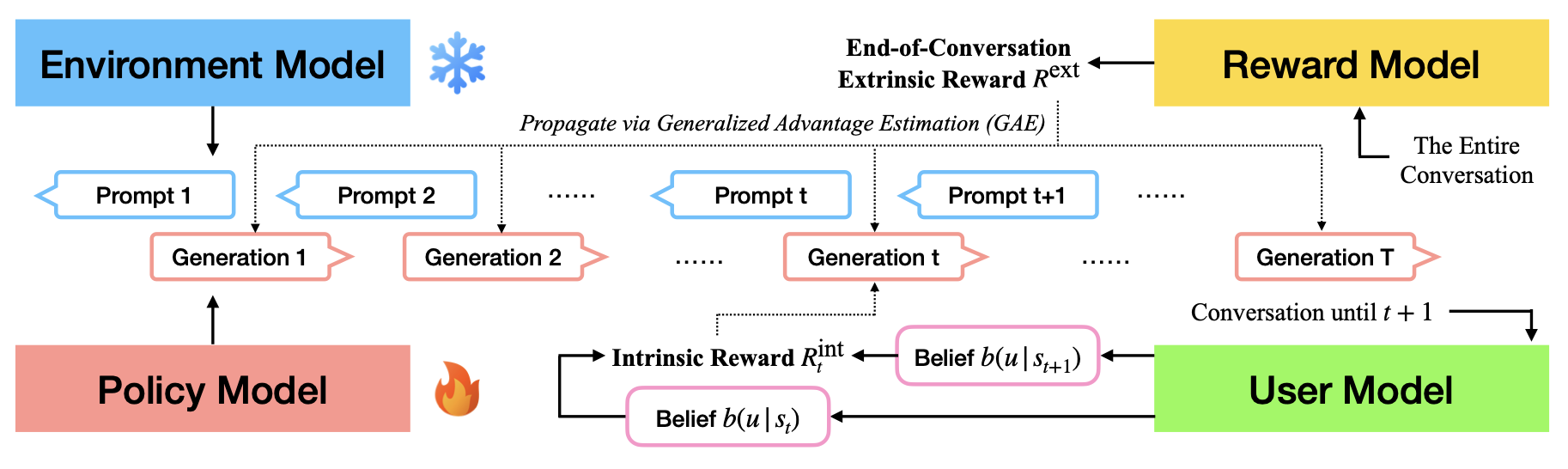
This inference of a user’s preferences is the key part of their method, as this determines the dense, intrinsic reward that they claim can improve personalization when added to sparse, end-of-conversation rewards. These intrinsic rewards are derived using the User Modeling LLM’s logits over the user’s type (which suggests we need to know a user’s ground truth “type” before training). And we can use those likelihoods as either:
- base likelihoods (the Policy Model should ask questions that maximize the User Model’s inference of the user’s true type)
- log likelihoods (as above, but with log likelihoods)
- negative entropy (the Policy Model should be reducing the User Model’s entropy about the user’s type – note that this does not require us to know the user’s ground truth preferences, but also does not guarantee that we’re increasing likelihood of the correct preferences.)
Finally, the authors frame these objectives as potential-based rewards, meaning that the objective is modified such that we optimize for improvements in each metric in each conversation turn, rather than simply trying to maximize the objective over the conversation.
Findings
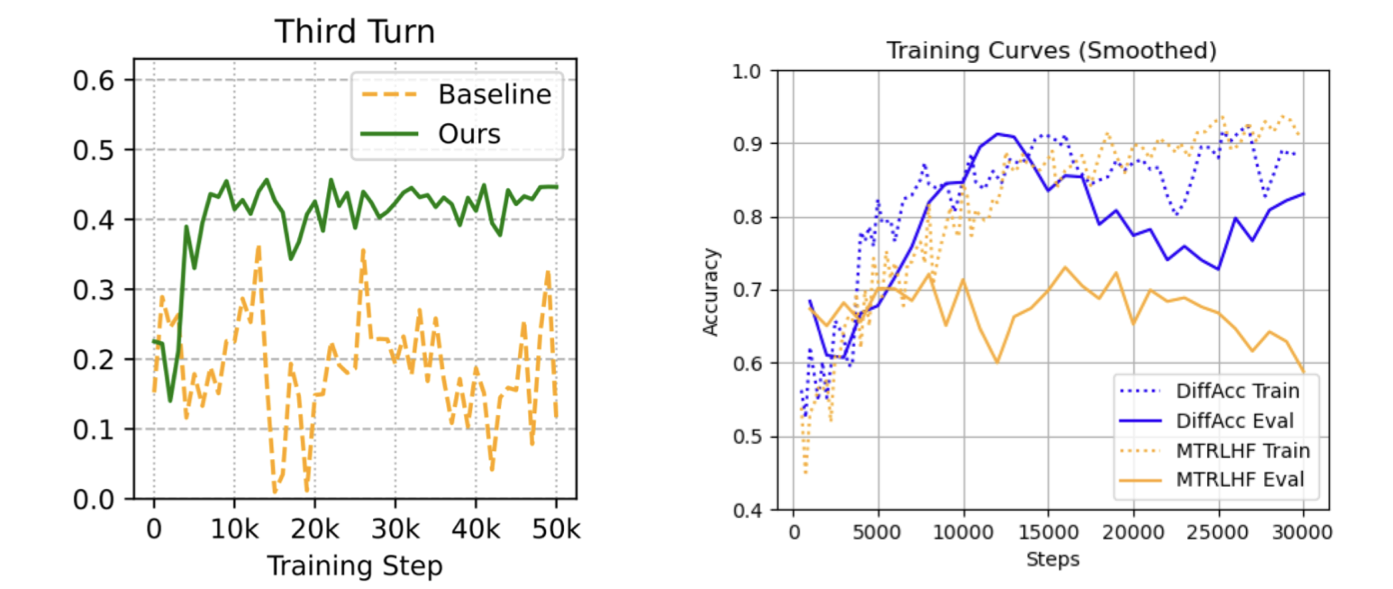
The authors find that their three auxiliary personalization objectives, particularly when framed as potential-based rewards, lead to significant improvements in personalization performance. Potential-based accuracy rewards (maximizing the base likelihoods) lead to a significant performance increase (from just ~68% up to ~87% success rates in suggesting personalized exercises), which makes sense given that this method assumes access to ground-truth information about the users. However, encouragingly, the potential-based negative entropy reward also leads to large improvements (up to ~84%), meaning that such improvements may not necessarily require prior knowledge about the user’s ground truth preferences. Unfortunately, this wasn’t a universal trend and the entropy-based methods ended up doing much worse on other evals (such as conversation quality and personalization for a more subtle task).
Takeaways
Reinforcement learning can effectively improve personalization beyond SFT on personalization data. While this isn’t news, it is good to see this borne out in the data and on the authors’ LLM-simulator setup.
Intrinsic rewards improve learning efficiency and efficacy when applying RL for personalization with LLMs. Particularly when there is ground-truth information about users, applying auxiliary objectives that encourage the LLM to produce conversations that reveal user preferences can lead to improved personalization.
Naively improving personalization performance can lead to drops in conversation quality. The authors find that several versions of their intrinsic rewards lead to reward-hacking behaviors such as arbitrary lengthening of responses, mode collapse to a single preference type, or “persuasion” behaviors (where the LLM tries to change the user’s preference rather than infer it). Looking through the appendix, it seems like the Environment Model (the LLM playing a synthetic human) tends to be very… LLM-y in its responses, leading to poor personalization performance and bad overall conversations, as the synthetic user opts to agree with suggestions and mindlessly agrees with everything that the Policy Model suggests, rather than behaving more like a real user.
Thoughts & Future work
I like the idea of adding some auxiliary objective to the LLM that focuses on the conversation as a whole, rather than just on the end-product. While the motivation of learning without labeled datasets didn’t entirely match the methods (which assumed access to labeled human preferences), I think the findings and lessons are valuable for future research, and there are plenty of avenues opened up by this work.
First, it would be interesting to explore how we might relax the assumptions that we must know a user’s preferences. Future work might explore more ideas like the entropy-based rewards in this work, where the LLM is encouraged to “find out more”, even if it doesn’t know exactly what it’s looking for.
Separately, it may be interesting to explore adding other objectives that improve the conversation quality or that help to mitigate reward hacking. For example, we could add dense rewards for conversations that are particularly informative, engaging, or thought-provoking, in addition to those that help reveal hidden preferences.
Finally, I appreciate the investment in modeling personalization as a multi-turn problem, in which the LLM has a chance to “talk” to a user before making a suggestion. Even so, this work assumes that users are static, and that preferences do not change with changing context (location, time-of-day, mood, etc.) or evolve over time. I’m interested in seeing future work that considers how preferences evolve over time or in response to changing settings.
References
[1] Wan, Yanming, Jiaxing Wu, Marwa Abdulhai, Lior Shani, and Natasha Jaques. “Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward.” arXiv preprint arXiv:2504.03206 (2025). https://arxiv.org/pdf/2504.03206